گزارش چهارمین نشست از سلسله نشستهای همایش «روشهای پژوهش در علوم انسانی و اجتماعی»

چهارمین نشست از سلسله نشستهای همایش «روشهای پژوهش در علوم انسانی و اجتماعی: رویکردهای نوپدید و چالشهای پیشرو» با سخنرانی دکتر مسعود قیوّمی و دکتر آتوسا رستمبیک، 11تیرماه 1402 در پژوهشگاه علوم انسانی و مطالعات فرهنگی برگزار شد.
جایگاه تحلیلهای داده محور در علوم انسانی دیجیتال
دکتر مسعود قیومی (دانشیار پژوهشکده زبانشناسی و مدیر همکاریهای علمی بینالملل)، سخنانش را با موضوع «جایگاه تحلیلهای داده محور در علوم انسانی دیجیتال» آغاز کرد و گفت: باتوجه به موضوع نشست، بهدنبال تحقق این نظر خواهیم بود که چگونه میتوان در چارچوب علوم انسانی دیجیتال از داده در تحلیلها استفاده کرد. وی شرح داد: علوم انسانی دیجیتال متشکل از دو بخش علوم انسانی و فناوری اطلاعات است که در کنار هم این مفهوم را شکل میدهد.
1 مقدمه
برای یافتن جایگاه تحلیلهای دادهمحور در چارچوب علوم انسانی دیجیتال نیاز است مفاهیم اولیهای مطرح شده و تعریف شود. ابتدا نیاز است با اصطلاح علوم انسانی دیجیتال و همچنین موضوعاتی چون سطوح کفایت چامسکیایی و همچنین زبانشناسی پیکرهای یک آشنایی اولیه صورت پذیرد.
1-1 علوم انسانی دیجیتال
براساس تغییرات جهان، پیرامون بشر امروز، حجم زیادی از اطلاعات انباشته شده است و منابع تولید اطلاعات بسیار متنوعی بهوجود آمده است. منابع این اطلاعات از تلفن همراه و رایانههای شخصی هر فرد گرفته تا پایگاههای داده، مراکز داده و منابع دیگر اطلاعاتی این محیط پیرامون را شکل میدهد. زمانیکه بحث علوم انسانی دیجیتال مطرح میشود، به این صورت میتوان تعبیر کرد که علوم انسانی دیجیتال محصول مواجه شدن علوم انسانی سنّتی(علوم انسانی رایج) و روشهای رایانشی و الگوریتمی است؛ بنابراین، مشترکات علوم انسانی و فناوری اطلاعات در کنار هم علوم انسانی دیجیتال را شکل میدهد بهگونهایکه یک فضای چندگانه ایجاد و از آن شرایط برای توصیف استفاده میشود تا به هدف غایی که همانا رسیدن به دانش است، دست یافته شود. وقتی راجع به علوم انسانی صحبت میشود، وارد یکسری جزئیاتی خواهیم شد که تلاش میشود به شیوه مناسب جزئیات توضیح داده شود. بعضی اوقات ممکن است ایدهها و مباحثی که مطرح میشود، دچار پارادوکس شود؛ درحالیکه ورود به حوزه رایانه به این معناست که مسائل خیلی دقیق و واضح بدون اینکه هرگونه ابهامی داشته باشد، مطرح شود و اطلاعات باید بهصورت نظاممند براساس ساختاری که در کامپیوتر وجود دارد برای حل مسائلی که در حوزه علوم انسانی است، استفاده شود (بوردیک و همکاران، 2012). بنابراین عبارات، علوم انسانی دیجیتال را به این صورت میتوان تعریف کرد که این موضوع انعکاس یافتههای نظری و روششناسی شناختهشده موجود در حوزه علوم انسانی است که در قالب دنیای دیجیتال امروز بهصورت کاربردی یا تهیه ابزاری برای بهدستآوردن دانش جدید مورد استفاده قرار میگیرد. هدف علوم انسانی دیجیتال صرفاً پردازش دادههایی که در حوزه علوم انسانی وجود دارد، نیست؛ در حقیقت هدف از این پردازش، رسیدن به دانش است. برای نشاندادن گستره علوم انسانی دیجیتال در پیشینه مطالعاتی میتوان به اصطلاحات زیر دست یافت که همگی ذیل چتر علوم انسانی دیجیتال مطرح میشود:
- فلسفه رایانشی (Computational Philosophy)،
- زبانشناسی رایانشی (Computational Linguistics)،
- میراث دیجیتال (Digital Heritage)،
- باستانشناسی دیجیتال (Digital Archaeology)،
- باستانشناسی رایانشی (Computational Archaeology)،
- معماری یارانشی (Computational Architecture)،
- تاریخ رایانشی (Computational History/Histoinformatics)،
- سیاست رایانشی (Computational Politics)،
- قانون رایانشی (Computational Law)،
- مطالعات حقوق رایانشی (Computational Legal Studies)،
- اقتصاد رایانشی (Computational Economics)،
- روانشناسی رایانشی (Computational Psychology)،
- علوم اجتماعی رایانشی (Computational Sociology)،
- مردمشناسی رایانشی (Computational Anthropology)،
- الهیّات رایانشی (Computational Theology)،
- کتابخانه دیجیتال (Digital Library) و
- روزنامهنگاری فناورانه (Technology Journalism).

دکتر قیومی ادامه داد: این نمونهها، حوزههایی از علوم انسانی است که بهنوعی با بحث فناوری اطلاعات درگیر شدهاست. در این موضوعات، یک بخش علوم انسانی و بخش دیگر فناوری اطلاعات است. شایان ذکر است بهدلیل ورود به فناوری اطلاعات، مباحث هوش مصنوعی و مانند آن مطرح میشود. اگر بخش علوم انسانی از فعالیتهایی که امروزه در حوزه مهندسی رایانه با کمک هوش مصنوعی انجام میشود جدا شود، قسمت مهندسی رایانه حرف زیادی برای گفتن نخواهد داشت، چون تحولاتی که در حال وقوع است با محوریت علوم انسانی مطرح میشود. بهعنوان مثال، اگر موضوع چتبات و نوع معروف آن که CHATGPT است را در نظر بگیریم، میبینیم که این فناوری چیزی نیست جز یک سامانه مکالمه-محور. مکالمه یکی از کاربردهای زبانی است که در حوزه زبانشناسی و بهطور خاص ذیل تحلیل گفتمان مطرح میشود. بنابراین، موضوع چتبات که رنگوبوی فناورانه دارد حاصل تعامل علوم انسانی و دانش رایانه است.
1-2 سطوح کفایت چامسکیایی
نوآم چامسکی، زبانشناس، فیلسوف، ریاضیدان و منتقد اجتماعی و فعال سیاسی آمریکایی، در سال 1964 بحث دستور زبان را مطرح کرد و برای اینکه دستور زبان بهعنوان یک مؤلفه علوم انسانی توصیف شود، سه سطح کفایت را معرفی کرد:
الف)کفایت مشاهدهای. هدف این کفایت تشخیص جملات دستوری از غیردستوری و دسترسی به دانش ناخودآگاه است. در این سطح به شمّ زبانی توجه ویژه وجود دارد. برای مثال جمله «حسن به مدرسه میروم» کاملاً مشخص است که غیردستوری است؛ چون شناسه فعل با فاعل تطابق ندارد.
ب) کفایت توصیفی: در این سطح از کفایت علّت دستوری یا غیردستوری بودن ساختهای زبانی را متوجه شویم، بهعبارتی باید بهدنبال علّت مبتنیبر شواهد باشیم.
ج) کفایت توضیحی (تبیینی): در این سطح باید بدون توجه به یک زبان خاص به دانش زبان برسیم و به علت بهوجودآمدن زبان بپردازیم. این دانش یک دانش انتزاعی است. اینکه انسان به چه صورت کار تفکر انجام میدهد و زبان را میآموزد و چگونه دانش زبانی در ذهن نهادینه میشود، مسائلی است که در این سطح به آن پرداخته میشود. اگر این سه کفایت در حوزه توصیف زبان را در نظر بگیریم، میتوانیم از آن برای سایر تحلیلهای حوزه علوم انسانی از آن استفاده کنیم.
1-3 زبانشناسی پیکرهای
در مطالعات زبانشناسی یک تغییر روششناسی اتفاق افتاده که از دهه 1960 آغاز شدهاست. بعداز سال 1964 که چامسکی سه سطح کفایت را مطرح کرد، در سال 1967 مطالعات زبانشناسی مبتنی بر پیکره زبانی که اصطلاحاً زبانشناسی پیکرهای نامیده میشود، مطرح شد. بهطورکلی، دو رویکرد در زمینه پژوهشهای زبانی مبتنیبر پیکره مطرح است که موجب تسریع این قابلیت به سایر حوزههای علوم انسانی میشود (توگنینی-بونلی، 2001):
الف) مطالعات پیکره-بنیان: در این مدل مطالعه، یک فرضیه وجود دارد و سعی میشود با بررسی حجمی از دادههای زبانی شواهدی از پیکره یافت شود که امکان قبول یا رد این فرضیه را فراهم آورد.
ب) مطالعات پیکره-محور: در این فرآیند هیچ فرضیه اولیه وجود ندارد و کفایت شهودی بررسی و تلاش میشود از کفایت شهودی به توصیفی دست یافته شود تا از توصیف به دانشی که کفایت تبیینی است، برسیم.
برای تحقق کفایت تبیینی میتوان از شیوههای رایانشی مبتنیبر علم داده استفاده کرد. رویکردهای پیکرهبنیان و پیکرهمحور این امکان را دارد که در سایر حوزههای علوم انسانی کاربردی شود.
در مطالعات پیکرهمحور، موضوعی با عنوان «علم داده» شکل میگیرد. در علم داده از فناوریهای اطلاعات و هوش مصنوعی برای تحلیل دادهها استفاده میشود. هدف علم داده بهدستآوردن دانش از دادهها و اطلاعات در محیط پیرامون است. علم داده دارای سه رکن است: علم آمار، علم فناوری اطلاعات و حوزه مورد نظر که قرار است بررسی شود. بهعنوان مثال زبانشناسی، مدیریت و غیره. هر حوزه متغییرهایی دارد که تلاش میشود با کمک علم آمار و فناوری اطلاعات از آن در حل مسئله کمک گرفته شود. تمرکز بر این سه رکن میتواند در حوزههای علوم انسانی به اهداف جدیدی دست یابد. هدف علم داده، کسب دانش است و این دانش درحوزههای علم، تجاری و صنعتی میتواند امکاناتی را برای زندگی بشر فراهم کند. کارکرد دیگر علم داده در سیاستگذاریهای کلان است به این صورت که دانش بهدستآمده از تحلیل دادهها بتواند در تصمیمگیریها یا تدوین برنامههای توسعهای استفاده شود. امروزه موضوع حکمرانی داده در محافل مدیریتی کشور مطرح است که بیانگر اهمیت توجه به این موضوع است. برای نمونه، اخیراً پلیس هوشمند مطرح شدهاست که هدف آن استفاده از علم داده برای مسائل امینی در جامعه ایران است.
۲ علم داده
علم داده با مطرحشدن موضوع کشف اطلاعات و تحلیل محتوایی در دهههای 1960 و 1970 میلادی شکل گرفتهاست (کائو، 2017). علم داده توسط توکی (1962) با عنوان «تحلیل داده» معرفی شدهاست. در همایش آمار در سال 1992، مفاهیم و اصول و روشهای آماری در تحلیل داده مشخص شد و مفهوم اولیه علم داده در سال 1998 توسط چیکیو هایاشی شکل گرفت (مورتاگ و دولین، 2018). که شامل طراحی، جمعآوری و تحلیل داده است.
علم داده مفهومی است که با علوم رایانه و آمار کره خوردهاست. در سال 1974، اصطلاح «علم داده» توسط پیتر نارو جایگزین «علم رایانه» شد، ولی مورد پذیرش جامعه علمی قرار نگرفت. در سال 1997 اصطلاح علم داده توسط جف وو بهجای «علم آمار» بهکار رفت که مجدداً در جامعه علمی آمار نیز مورد پذیرش قرار نگرفت (وو، 1997). نهایتاً باتوجهبه تحولات فناورانه دیجیتال و نهادینهشدن آن در جامعه در دهههای 1980 و 1990، مفهوم امروزی علم داده توسط کلوند (2001) ارائه شد که متشکل از علم آمار و داده کاوی است.
1-2 رابطه میان علم داده، تجزیه و تحلیل داده و تحلیل داده
تحلیل داده حوزه دیگری است که توسط توکی (1962) در علم داده در نظر گرفته شد. اما تحلیل داده جای خود را به تجزیه و تحلیل داده سپرد. کائو (2017) مفهوم نوینی از تجزیه و تحلیل داده ارائه کرد که برگرفته از توسعه داده کاوی است و هدف آن کشف دانش و یادگیری ماشین بههمراه مفهوم اولیه تحلیل داده است و در آن تلاش میشود تجزیه و تحلیل توصیفی حاصل از آمار توصیفی بهدست آید. با این حال، میان علم داده و تجزیه و تحلیل داده تمایز وجود دارد. آشیم و دیگران (۲۰۱۵) و فیاد و هموتچو (۲۰۲۰) تفاوت میان این دو را تا حدودی مشخص کردهاند که در زیر خلاصه شدهاست:
الف) میل علم داده بیشتر بهسمت تحلیل پیشگویانه و فراهمآوردن تصویر کلی است درحالیکه تجزی و تحلیل داده میل کمتری به تحلیل پیشگویانه داشته و در آن تلاش میشود وضعیت حال توصیف شود.
ب) در علم داده بیشتر از یادگیری ماشین استفاده میشود درحالیکه در تجزیه و تحلیل داده استفاده از یادگیری ماشین کمتر است.
پ) در علم داده از هر دو داده ساختاریافته یا ساختارنیافته استفاده میشود درحالیکه در تجزیه و تحلیل کلام از یک منبع داده ساختاریافته استفاده میشود.
ت) در علم داده از روشهای پیکرهمحور و بدون وجود فرضیه اولیه استفاده میشود. در علم داده پیشپردازش داده نیاز است و موضوع کلانداده مطرح میشود. درحالیکه در تجزیه و تحلیل داده از روشهای پیکرهبنیان مبتنیبر وجود فرضیه استفاده شده و در آن تلاش میشود با جستوجو در داده الگو از دادههای ساختارمندیافته تهیه گردد.
میان تجزیه و تحلیل داده و تحلیل داده تفاوتهایی وجود دارد. در تجزیه و تحلیل دادهها برای پردازش دادهها از انواع فناوریها استفاده میشود و در آن تلاش میشود با کمک فناوری دانش مخفی کشف شود. در این فرایند از تجزیه و تحلیل توصیفی و تحلیل استنباطی استفاده نمیشود. درحالیکه در تحلیل داده از ابزارهای آماده آماری استفاده شده و به استفاده از تحلیل استنباطی به تحلیل توصیفی پرداخته میشود و در آن دانش مخفی کشف نمیشود.
۲-۲ رابطه داده، اطلاعات و دانش
در مقدمه گفته شد که در علم داده بهدنبال کسب دانش هستیم. نیاز است بدانیم چه رابطه بین داده و دانش وجود دارد. نکته قابل تأمل این است که دانش بهسادگی و تصادفی حاصل نمیشود. دانش وابسته به اطلاعات موجود در داده است. بنابراین بین اطلاعات و داده تفاوت وجود دارد. اگر سلسلهمراتب دانش در شکل ۱ را در نظر داشته باشیم سه مفهوم اطلاعات، داده و دانش در یک هرم به این صورت در نظر گرفته شود که پایین هرم داده است و بالای هرم دانش است و میان این دو اطلاعات وجود دارد.
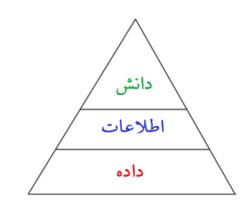
شکل ۱: هرم دانش
به اعتقاد برین (۱۹۹۵)، داده، مواد خام است و هیچ پردازشی بر روی آن صورت نگرفته است و اطلاعات، دادههای معنادار و کاربردی است تا بتوان دانش را از آن استخراج کرد. روچستر (۱۹۹۶) میگوید اطلاعات مجموعهای از دادههای سازمانیافته است. میدو و یووان (۱۹۹۷) معتقدند که داده دارای معنای کم یا بدون معناست و اطلاعات حاوی معنا و برای ماشین دارای اهمیّت است و دانش انباشت و ادغام اطلاعاتی است که به واسطه پردازشهای ماشینی استخراج میشود. درتسکه (۲۰۰۰) اذعان میدارد که اطلاعات صورتی است که دارای تجلی عینی است و دانش خصیصه صورت است. لنسکی (۲۰۰۴) داده را عناصر ملموس میداند. اطلاعات لایه میانی بین عناصر ملموس و سطح انتزاعی است و دانش سطح معنایی انتزاعی است. دالکیر (۲۰۰۵) داده را محتوایی تعریف کردهاست که قابل دیدن یا قابل تغییر باشد؛ اطلاعات بازنمایی داده تحلیلشده است و دانش اطلاعات نظری و مفید است.
3-2 بخشهای علم داده
علم داده از ۷ بخش تشکیل شدهاست که در ادامه توضیح داده میشود.
1-3-2 درک مسأله
در درک مسئله موضوعی که مدنظر است، بررسی میشود و درک عمیقی نسبت به مسئله ایجاد میشود. براساس آن سؤالات مطرح و اهداف تعیین شود. متغییرها یافت شده و راهکاری برای ارزیابی راه حل آن مسئله مشخص میشود. براساس این اطلاعات نقشه راه ترسیم میشود. در این فرایند به پیشینه نیز توجه میشود تا مشخص چه کسانی درمورد آن مسئله تجربه دارند تا از تجربیات آنان نیز استفاده شود. بنابراین، درک مسئله، بهعنوان مرحله اول در علم داده بسیار پراهمیت است.
۲-۳-۲ جمعآوری داده
در این مرحله به گردآوری داده توجه میشود. هر نوع دادهای نمیتواند برای هر کاری مفید باشد. در علم داده دادههایی مفید است که به حل مسئله کمک نماید. بنابراین، درک مسئله اثر بسیار مهمی بر تعیین نوع دادههایی که باید گردآوری شود، دارد. انواع دادهها عبارت است از صوتی، تصویری، متنی و عددی. منابع که میتواند برای جمعآوری انواع دادهها استفاده شود عبارت است از وب، بایگانیها، کتابخانهها و غیره. اکنون که منابع و نوع دادهها مشخص شد باید به شیوه گردآوری دادهها پرداخت که عبارت است از خزش از وب، جمعسپاری در محیط وب و توزیع پرسشنامه.
پس از گردآوری دادهها دو موضوع مطرح میشود. یکی موضوع ذخیره داده است که بحث پایگاه داده در این زمینه مطرح میشود و دیگری موضوع چگونگی استفاده از دادهها است. گفتنی است در جمعآوری داده، بحث کلانداده مطرح میشود. کلانداده، به مفهوم حجم زیادی از داده است و سرعت در تولید محتوا نیز در کلانداده مطرح است. وجود عدم قطعیّت در صحت دادهها هم ازجمله مباحث دیگری است که حائز اهمیّت میباشد، بهعنوان مثال اخبار جعلی که در حوزههای متفاوت مطرح میشود. باید راهکاری را ایجاد کنیم، چون از منابع مختلفی برای کسب داده استفاده میشوند. در بحث دادهها، پیش پردازش خواهیم داشت،
3-3-2 پیشپردازش داده
دادههای بسیار متنوعی در کلانداده از منابع مختلف بهدست میآید، از این جهت نمیتوان بهطور مستقیم دادههایی که بهدست میآید را استفاده کرد. برای رفع این مشکل باید پیشپردازش انجام شود تا یکدستی نسبی در دادهها ایجاد شود و دادههای ناقص برای جلوگیری از نوفه پالایش شود.
4-3-2 دادهکاوی
برای اینکه بتوانیم از دادهها استفاده کنیم میتوانیم الگوها و رفتارهای موجود در دادهها را بهنوعی بیابیم و جستوجو کنیم. این کار بهصورت الگوریتم پردازشی انجام میشود. چنانچه دادههایی که قصد پردازش داریم دادههای متنی باشد به آن متنکاوی گفته میشود. در دادهکاوی بحث پایگاه داده را خواهیم داشت و سپس یادگیری ماشین و هوش مصنوعی مطرح میشود.
5-3-2 تعیین ویژگیها
گام اول علم داده درک مسئله بود. در گام چهارم تلاش شد از روشهای دادهکاوی برای حل مسئله استفاده شود. برای پردازشهای الگوریتمی نیاز است ویژگیهایی از داده استخراج شود تا از کنار هم قرار گرفتن ویژگیها یکسری الگو بهدست آید و از آن در مدل پردازشی استفاده شود. این ویژگیها نوعی بازنمایی محتوایی از دادهها نیز تلقی میشود و انتخاب آن از اهمیت بهسزایی برخوردار است. اهمیت آن به حدی است که چگونگی انتخاب ویژگی را با اصطلاح مهندسی ویژگی نیز یاد میکنند. بهترین ویژگیها در یک مدل تجربی مبتنیبر سعی و خطا بهدست میآید.
6-3-2 مدلسازی داده
اساساً مدلسازی که در حوزه رایانه وجود دارد مبتنی بر شناخت انسان از محیط اطراف استوار است. مدلسازی چگونگی عملکرد مغز در محیط رایانه سبب ورود به بحث یادگیری ماشین میشود. در یادگیری ماشین نیاز است از میان دادهها ویژگیهای مفید استخراج شود و در یک فرایند پردازشی مورد استفاده قرار گیرد.
دو روش کلی یادگیری ماشین وجود دارد: الف) یادگیری بانظارت: در این نوع یادگیری، یک مدل با استفاده از دادههای ورودی برچسبخورده اولیه آموزش میبیند تا بتواند خروجی را برای دادههای جدید دیدهنشده را پیشبینی کند. انواع الگوریتمهای یادگیری با نظارت عبارت است از: نزدیکترین k همسایه ، رگرسیون خطی، رگرسیون لاجیستیک، ماشینبردار پشتیبان، درخت تصمیم، جنگل تصادفی و شبکه عصبی. برای مثال، میتوان دادههایی که حاوی واژه و مقوله دستوری واژه است را به الگوریتم پردازشب داد و مدل زبانی را تهیه کرد و سپس یک جمله جدید دیدهنشده را بهعنوان داده آزمون به مدل داد و از آن خواست تا مقوله دستوری واژههای جمله ورودی را مشخص کند.
ب) یادگیری بدون نظارت: در این نوع یادگیری، الگوهای مخفی یا ساختارهای ذاتی بدون آموزش با استفاده از داده آموزش، بهطور خودکار از دادههای ورودی استخراج میشود. در این یادگیری، دادهها را بر اساس تشابه یا تفاوت بین دادهها خوشهبندی میشود. خروجی این مدل آموزشی خوشههایی با برچسبهای نامعین و کلی است که نیاز است برای قابلفهمشدن توسط ناظر انسانی برچسبگذاری شود. در خوشهبندی از تشابه و تفاوت بین دادهها استفاده میشود. الگوریتمهای خوشهبندی به دو دسته تقسیم میشوند: خوشه و سلسلهمراتبی. خوشهبندی سلسله مراتبی میتواند از بالا به پایین باشد یا برعکس.
7-3-2 تجزیه و تحلیل و بازنمای بصری
بحث تجزیه و تحلیل کیفی و بازنمایی بصری قسمتی از علم داده است که اهمیت بهسزایی در حل مسئله دارد. این دو یکی از راهکارهایی است که به انسان کمک میکند تا به درک عمیق برسد. وجود بازنمایی بصری، مثل نمودارها، سبب میشود تا به درک عمیقتر دست یافته شود.
۳ نمونه عملی تحلیلهای دادهمحور
سامانه تحلیل مستندات علمی نمونه سامانهای است که در آن تلاش شدهاست در چارچوب علوم انسانی دیجیتال به تحلیل دادهمحور مقالات علمی نگارششده به زبان فارسی بپردازد. در این پژوهش، حجم زیادی از مقالات از وبگاههای مختلف خزش شده و پالایش شدهاست و به شکل یک پایگاه داده ساختارمند شدهاست. بعضی از دادهها حاوی برچسب موضوعی بود و برخی نبود. ازاینرو، پس از پالایش دادهها و محدودکردن آن به مقالات علوم انسانی، یک مدل پردازشی تهیه شد که بتواند مقالات را به یکی از حوزههای 16گانه در علوم انسانی تخصیص دهد. در مرحله بعد، تحلیل موضوعی مقالات با استفاده خوشهسازی انجام شد. این پردازش بر این ایده بنا نهاده شدهاست که هر مقاله از چندین موضوع تشکیل شدهاست و هر موضوع نیز با واژههای خاصی بیان میگردد. بنابراین قرارگرفتن مقالات مشابه در یک خوشه بیانگر وجود تشابه در موضوع بحثشده در مقالات است. با شمارش مقالات در هر خوشه میتوان به توزیع آماری مقالات دست یافت. این مقالات در زمانهای مختلفی منتشر شدهاست که میتوان مؤلفه زمان را نیز در تحلیل وارد کرد و اطلاعات را براساس بازه زمانی مورد نظر استخراج کرد. میتوان خوشهها را براساس موضوعات درون هر خوشه برچسبگذاری کرد و معنای عمیقتری به تحلیل رایانشی بخشید. نمایش بصری خوشهها در این سامانه وجود دارد. ویژگی نمایش بصری در این است که میتوان بهلحاظ گرافیکی خوشههایی که از نظر موضوعی به یکدیگر نزدیک است یا تداخل موضوعی ممکن است در آنها پدید آید را مشاهده کرد. در این سامانه امکان جستوجوی مقالات مشابه براساس عنوان و چکیده وجود دارد که میتواند نقش بهسزایی در کمک به دانشجو برای یافتن مقالات یا عناوین مشابه با محتوا یا عنوان پیشنهادی توسط وی ایفا کرد.
۴ جمعبندی
در مطالعات مرتبط با حوزه علوم انسانی، رویکرد دادهبنیان و رویکرد دادهمحور بسیار پرکاربرد است. رویکرد دادهمحور، توجه خیلی زیادی را به خود جلب کردهاست. علم داده مبتنیبر این نوع رویکرد است. ازآنجاکه امروزه در محیط اطرافمان دادههای متنوعی وجود دارد استفاده از علم داده اجتنابناپذیر است. برای فائق آمدن بر شرایطی که در جهان پیشرو برای مطالعات مربوط به علوم انسانی و اجتماعی میتوان متصور شد این است که با آغوش باز از فناوری اطلاعات در حوزه علوم انسانی دیجیتال برای مطالعات استفاده شود. برای ورود به این حوزه میتوان با شیوه مطرحشده در علم داده به بررسی مسئله علوم انسانی و اجتماعی پرداخت.

علوم انسانی رایانشی؛ معرفی چند ابزار
سخنران بعدی نشست، دکتر آتوسا رستمبیک (دانشیار پژوهشکده زبانشناسی و مدیر گروه زبانشناسی عمومی) سخنانش را با موضوع «علوم انسانی رایانشی؛معرفی چند ابزار» آغاز کرد و گفت: اغلب پژوهشگران حوزه علوم انسانی کاربر نرمافزارهایی که در سخنرانی «جایگاه تحلیلهای دادهمحور در علوم انسانی دیجیتال (دکتر مسعود قیومی) مطرح شد»، هستند. امروزه شاهد این هستیم که تحلیلهای رایانشی در بسیاری از حوزههای علوم انسانی به کار گرفته میشود و نرمافزارهای تحلیل کیفی، کمی و محاسبات آماری گوناگونی در دسترس پژوهشگران قرار دارد. در ادامه به برخی از این نرمافزارهای کاربردی و برخی از چالشهای رایانشی شدن علوم به ویژه علوم انسانی پرداخته میشود.
امروز از علوم انسانی رایانشی،Techno- humanities نام برده میشود که منظور بهکارگیری فناوری (تکنولوژِی) در علوم انسانی است که مهمترین آن شاید همان فرآیند دیجیتالی شدن دادهها، پرسشنامهها و فرایند تحلیل باشد که در مقابل علوم انسانی سنّتی مبتنی بر مشاهده و استفاده از کاغذ، مصاحبه، پرسشنامه کاغذی و ... قرار میگیرد. ابتداییترین پیامد علوم انسانی رایانشی حذف کاغذ و جایگزینی آن با متون دیجیتال است. امروزه دیگر بحث انتخاب و علاقه به علوم انسانی رایانشی مطرح نیست؛ بلکه صحبت از یک ضرورت و نیاز است. هر یک از ما در سطحی با متون الکترونیک دیجیتال سروکار خواهیم داشت؛ متونی که قالبهای(format) مختلفی دارد، گاهی بهصورت عکس ذخیره میشوند و پژوهشگر با این آرشیوهای دیجیتالی مواجه است و کتابها و کتابخانههای دیجیتالی اصلیترین منابع در دسترس او هستند. در چنین شرایطی، آشنایی با انواع فرمت داده دیجیتالی، چگونگی تبدیل آنها به یکدیگر، همخوانی نداشتن فرمتها با تنظمیات برخی از رایانهها از جمله چالشهایی است که پژوهشگر روزانه با آنها مواجه است. در نهایت با نگاهی تخصصیتر، پژوهشگران اغلب مجبور هستند با دادۀ بازی که در فضای مجازی در اختیار دارند کار کنند، داده معتبر را از غیرمعتبر شناسایی کنند و بر مبنای همان پیکره داده دیجیتالی تحلیلهایشان را انجام دهند. تحلیلهای مبتنی بر پیکره بهویژه در علوم انسانی، چه از منظر کیفی و چه کمّی این امکان را فراهم میآورد، که نتایج قابل اعتمادتری ارائه شوند و پژوهشگر صرفاً برمبنای برداشت شخصی خود تحلیلی ارائه ندهد، بلکه بر مبنای حجم زیادی از داده صحبت خواهد کرد، امکان دفاع از مطلبی که بیان میشود وجود دارد. این حداقل دستاورد استفاده از پیکرههای بزرگ و بهکارگیری ابزارهای تحلیل رایانشی کمّی و کیفی در علوم انسانی است.
بیشک، این دیجیتالی و رایانشی شدن داده، کل فرایند پژوهش را تحت تأثیر قرار میدهد. از گردآوری داده تا ارائۀ نتایج. امروزه، ابزارهای مختلفی برای گردآوری دادهها بهصورت صوتی و تصویری وجود دارد و روز به روز به تعداد و تنوع و کیفیت آنها افزوده میشود. این تغییر و تحوّل را نمیتوان نادیده گرفت و یا بر استفاده از روشهای سنّتی اصرار ورزید. این مسائل بیتردید روند پژوهش و عملکرد پژوهشگر را تحت تأثیر قرار میدهند. پس آیا ممکن است با علوم انسانی دیجیتال در ارتباط نباشیم؟ پاسخ منفی است، زیرا اگر مستقیماً هم به این حوزه ورود نکنیم، از تغییراتی که رایانشی شدن علوم در پی دارد، متأثر هستیم و در صورت همراه نشدن با فناوریها، در نقطهای از مسیر پژوهش، با مانعی برخورد خواهیم کرد که بهطور کلی از مسیر باز میمانیم. امروزه پژوهشهای بین رشته یا میان رشته یکی از موضوعات بسیار مهّم و مورد توجه است. پژوهشگران باید این توانایی و ظرفیت را داشته باشند که خود بهطور مستقیم کاربر نرمافزارها و ابزارهای رایانشی نیستند، با پژوهشگران دیگر که از این نرمافزارها استفاده میکنند، همکاری داشته باشند. بنابراین لازم است که درک کنند چه موضوعی در جریان است، با اصطلاحات حوزه مورد نظر آشنا باشند و درواقع همه پژوهشگران ناگزیر هستند هرچند اندک، اطلاعاتی در این زمینه داشته باشند. نمودارهای 1 انواع داده دیجیتالی در دسترس برای پژوهشگران را نمایش میدهند.
نمودار 1- انواع داده دیجیتالی
آیا همه این تغییرات و نتایج آن مثبت بوده است؟ در واقع اینطور نیست. دیجیتالی شدن، نقاط مثبت و منفی دارد. برخی از نقاط قوت بهکارگیری رایانه و نرمافزارهای رایانشی در علوم انسانی به این شرحند: سرعت و دقّت بالا میرود و جابهجایی داده راحتتر صورت میگیرد، حجم زیادی از داده(مثلاً با فلش) قابل انتقال است بهجایی اینکه لازم باشد برگههای متعددی را همراه داشتهباشیم. امکان داشتن دادههای چند رسانه وجود دارد که بهویژه در حوزه علوم انسانی که هدف آن بهطور کلی شناخت انسان است، اهمیت بسیاری مییابد. مطالعۀ رفتار انسان در موقعیتهای مختلف یا ارتباطات انسانی، اکنون با وجود ابزارهای مختلف ضبط صوت و تصویر و ویدئو بیش از پیش ممکن شده است. بهعنوان نمونه، در حوزۀ مدیریت، آنچه بر اساس ارتباطات شخصی یا مطالعۀ شیوه مدیریت فردی بهدست داده میشود و یا حوزۀ زبانشناسی تحلیلها و بحثهای زبانی فقط مبتنی بر یک یا چند متن محدود هستند، به ارائۀ تحلیلی کامل و قابل تعمیم از یک پدیده نمیانجامند. برای حل این مسائل است که شیوهها و ابزارهای نوین پیشنهاد شدهاند؛ از جمله استفاده پژوهشگر از ابزارها و تحلیلهای چند رسانهMultimodal analysis . بهعنوان نمونه در حوزۀ تحلیل گفتمان، با استفاده از شیوۀ تحلیل گفتمان چندرسانهای یا چندوجهی تحلیل نه تنها مبتنی بر متن نوشتاری یا گفتاری است بلکه شیه حرکت حتی پلک زدنهای فرد نیز در تحلیل وارد میشود. مطابقۀ محتوا، با صوت و شیوۀ بیان و نیز زبان بدن سخنگو ارائۀ تحلیلی جامع را میسر میکند. بدون وجود این ابزارها و تحلیل ها، کاستیهای پژوهشها بیشتر خواهد بود. تحلیلهای کمیّ دقیقتر و گستردهتر بدون نیاز به داشتن دانش آماری تخصصی، تحلیلهای کیفی مبتنی بر پیکره و دسترسی به حجم زیاد داده، از جمله نقاط مثبت علوم انسانی دیجیتال است.
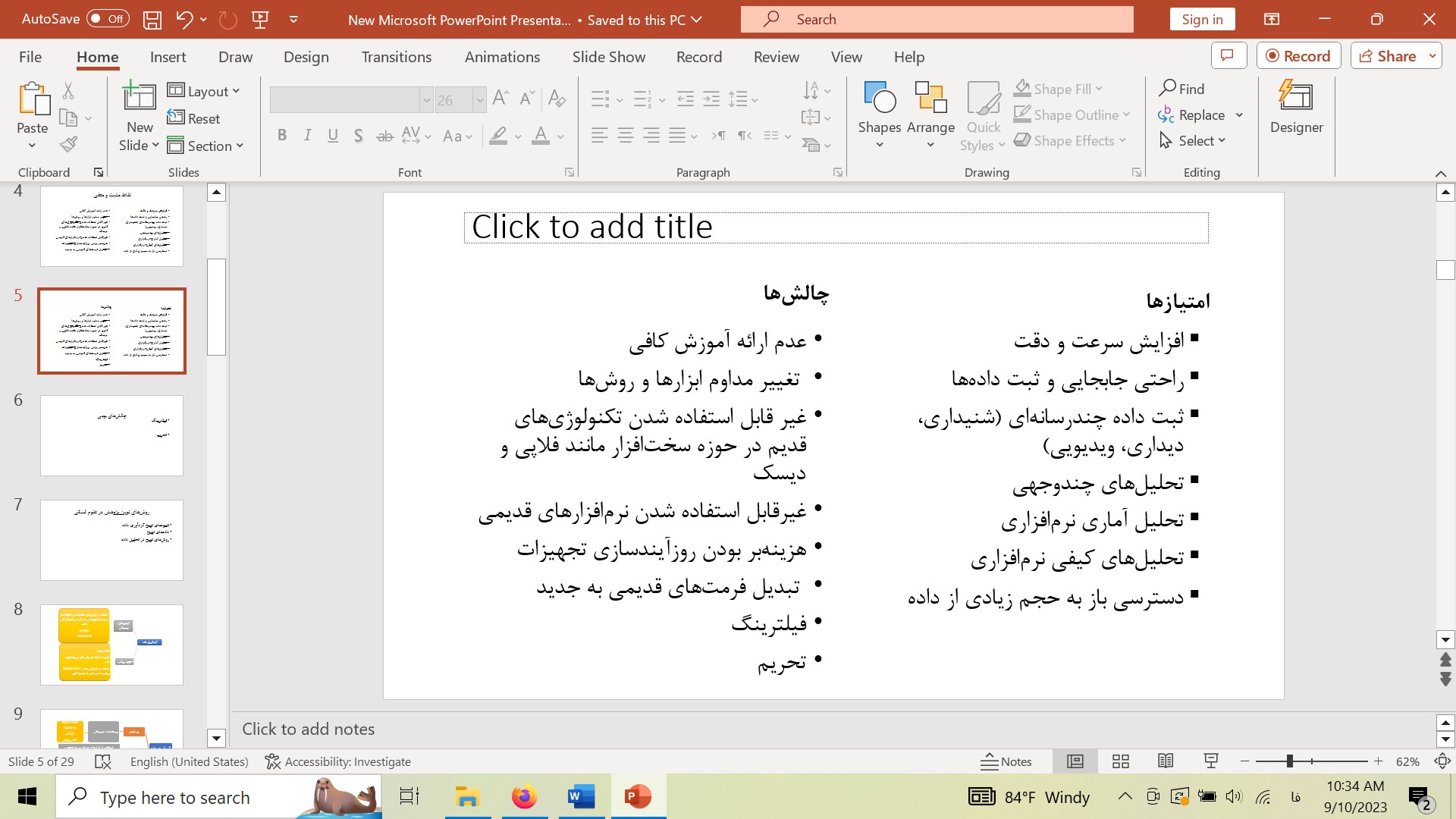
چالشهای پیشرو در دیجیتالی و رایانشی شدن علوم انسانی چیست؟ در پاسخ از میان نقاط ضعف علوم انسانی دیجیتال به چند مورد ملموس توجه کنید: آیا در دانشگاهها و پژوهشگاههای سطح کشور به دانشجویان و پژوهشگران آموزش کافی و کاربردی داده میشود؟ این امکان در سطح کشور بهصورت بسیار محدود صورت میگیرد. یک موضوع مهّم دیگر، تغییر مداوم و ارتقاء ابزارها هستند، که این موضوع نیازمند آموزش به کاربران است. روزآمد بودن در استفاده از نرمافزارها موضوع بسیار مهّمی است که چندان مورد توجه مدیران سازمانهای فعال در علوم انسانی قرار نمیگیرد. غیرقابل استفاده شدن تکنولوژیهای قدیمی، که شامل تجهیزات نرمافزاری و سختافزاری کامپیوترها میشود، نیاز به روآیند کردن آنها را به همراه دارد یعنی باید بودجهای برای این موضوع در نظر گرفته شود. از چالشهای دیگر، دسترسی به ابزارها و دادههای دیجیتالی است که گاهی با موانع پیش بینی نشده مواجه میشویم. بهعنوان نمونه، یکی از ابزارهای کاربردی جدید، نمایش دیداری تحلیلها یا انجام فرآیند تحلیل با استفاده از نقشه است. یکی از نرمافزاری که در حوزه گویششناسی پرکاربرد است، نرمافزار گب مپ Gabmap نام دارد. در این نرمافزار، مکانی(جایگاهی) پژوهشگر قصد دارد گویش آن منطقه را بررسی کند بر روی نقشه دیجیتالی مشخص میشود. نقشه که وارد نرمافزار میشود از طریق گوگل اِرث Google Earth بهدست داده میشود. حدود یک سال و نیم گذشته که در حال آموزش این رنم افزار به دانشجویان دوره دکترا بودم، تارنمای گوگل ارث فیلتر شد. به این ترتیب، علاوه بر محدودیتهایی که ذاتی کاربست ابزارهای رایانشی و دیجیتالی هستند، فیلترینگ نیز از دیگر محدودیتهای پیش روی پژوهشگران است. امکان آشنایی با نرمافزارها در YouTube موجود است که دسترسی به یوتیوب در ایران فیلتر است. مسئله دیگر تحریمها است، برای استفاده از بسیاری از نرمافزارها باید هزینه پرداخت شود که بهدلیل تحریمها برای پژوهشگر ایرانی امکان پرداخت وجود ندارد. بسیاری از سایتها فیلتر شدهاند و از طرفی بهدلیل تحریمها حتی دسترسی به سایتهای دانشگاهی محدود شده است. هنگامیکه از علوم انسانی دیجیتال و تشویق پژوهشگر به استفاده از ابزارها صحبت میشود، باید دسترسی به ابزار برای پژوهشگر فراهم شود، این موارد از مسائلی است که باید سیاستگذاران پژوهش کشور به آن توجه داشته باشند. این موضوع با عنوان چالشهای بومی مطرح میشود. همانطور که پیشتر اشاره شد، دیجیتالی شدن تمام سطوج پژوهش را متأثر کرده است. نه تنها با نوع داده جدیدی روبهرو هستیم، گردآوری داده نیز به شیوه جدید صورت میگیرد و به عبارتی داده، گردآوری و روشهای تحلیل آن تغییر کردهاست. چالش پیشروی پژوهشگر ایرانی در گردآوری داده چیست؟ استفاده از آرشیوهای دیجیتال مؤسسات، دانشگاهها و پژوهشگاهها موضوعی است که «تحریم» بسیار خودنمایی میکند زیرا در بسیاری از موارد پژوهشگران دسترسی به آرشیوهای مذکور را نخواهند داشت. در استفاده از داده دیجیتال، توصیه میشود که از گوگل و از موتورهای جستوجوی عمومی در مورد موضوع مورد نظر استفاده نشود، بلکه از داده گردآوری شده توسط دانشگاهها و مؤسسات استفاده شود. زیرا مؤسسات به آن داده بهگونه شکل دادهاند که پژوهشگر میتواند به داده مرتب شده و مقولهبندی شده دسترسی داشته باشد. از پژوهشهای پیکره_بنیاد نیز، به پژوهشگران توصیه میشود که از پیکرههای از پیش تهیه شده و آماده استفاده کنند، حال آنکه در ایران هنوز در حوزه تهیه پیکره بهصورت نظاممند و هدفمند کارهای بسیاری باید صورت گیرد و کاستیهای بسیاری وجود دارد؛ بهگونهای که در بسیاری موارد پژوهشگر مجبور میشود با استفاده از موتورهای جستوجوی عمومی به گردآوری داده و تهیه پیکره بپردازد که قطعاً کاستیهای بسیاری خواهد داشت. جدول 1- برخی از نقاط مثبت و منفی دیجیتالی و رایانشی شدن علوم انسانی را نمایش میدهد.
جدول 1- برخی از برجستهترین امتیازها و چالشهای دیجیتالی شدن علوم انسانی
شیوه دیگر گردآوری داده در علوم انسانی دیجیتال، استفاده از پرسشنامههای دیجیتالی است که چه توسط تارنماهای خارج از ایرانی و چه ایرانی در دسترس پژوهشگران قرار دارند. پرسشنامه برخط (آنلاین) این امکان را فراهم میکند که با ارسال پیوند (لینک) به افراد پرسشنامه تکمیل میشود. نسخههای پیشرفته این نرمافزارها هرکدام قیمتی دارد و هر چقدر پیشرفتهتر باشد، قیمت بیشتر میشود و در برخی موارد نرمافزار قابلیت انجام تحلیل و نمایش نتایج را نیز دارد. به این ترتیب، شاید تنها کاری که پژوهشگر باید انجام دهد، تهیه پرسشهای صحیح میباشد، ادامه کار را نرمافزار انجام میدهد. اگر کار با نرمافزارها بین پژوهشگران رایج شود، انجام بسیاری از پژوهشها حتی در سطح بینالمللی تسهیل میشود. مصاحبهها دیگر مثل قدیم صورت نمیگیرد، زیرا در گذشته صرفاً از یک ضیط صوت (رکوردر) استفاده میشد در صورتیکه اکنون صوت و تصویر باهم ضبط میشود. جهت پیادهسازی فایل صوتی ابزارهای مختلفی وجود دارد؛ از جمله نرمافزارهایی که صوت را به متن تبدیل میکنند.
همانطور که پیشتر اشاره شد، تحول در علوم انسانی با رایانشی و دیجیتالی شدن فرایند پژوهش در بخش تحلیل نیز مشهود است. برای نمونه به انجام تحلیل آماری اشاره میشود. پیشتر تحلیلهای آماری بهصورت دستی انجام میشد و بدون دانش دانش آماری ممکن نبود. امروز ابزارهای تحلیل کمّی گوناگونی در دسترس است که یکی از آنها نرمافزار اِس پی اِس اِسSpss است که بسیاری از تحلیلها در حوزه علوم اجتماعی و زبانشناسی اجتماعی با استفاده از این نرمافزار صورت میگیرد بدون آنکه پژوهشگر نیاز به داشتن دانش ریاضی و آماری تخصصی داشته باشد. سرعت و دقت در این نوع تحلیل قابل قیاس با تحلیلهای غیررایانشی نیست. حجم زیاد داده در چندثانیه به شیوههای گوناگون تحلیل میشود و نتایج نیز به شیوههای تصویری گوناگون نمایش داده میشود.
در ادامه برخی از ابزارهای رایج در پژوهشهای حوزه علوم انسانی به اختصار معرفی میشوند. از متداولترین متنهای دیجیتالی کتابهای صوتی audiobook و کتابهای الکترونیک Ebook هستند. امروزه، نسخههای چاپی کاربرد چندانی ندارند. تصویرهای دیجیتالی از منابع داده بسیار حائز اهمیّت به ویژه در علوم انسانی هستند؛ به عبارتی متن به تنهایی نمیتواند پاسخگوی نیازهای پژوهشی در حوزه علوم انسانی باشد. «داده باز» اغلب ساختار یافته هستند و رایانه نیز میتواند آنها را خوانش کند، بر روی داده ساختار یافته پردازش صورت میگیرد مانند خروجیهای آماری Excel. کلانداده، که دادههای بسیار بزرگی هستند که کامپیوتر معمولی (کامپیوتر پیسی) نمیتواند تحلیلهای آن را انجام دهد و نیاز به سرورهای پیشرفته و بزرگ است و عموماً برای سازمانهای بزرگ مورد استفاده قرار میگیرد. جهت جلوگیری از تمرکز بر روی متن اغلب سعی میشود در پژوهشها از دادههای چند رسانه استفاده شود.
تحلیل دادههای دیجیتالی مبتنی بر نوع داده صورت میگیرد. هر کدام از دادهها ابزارهای تحلیل خاص خود را دارند، داده متنی که به کمک رایانه میتواند تحلیل شود؛ سادهترین نمونه آن در نرمافزار وُرد، شمارش تعداد واژه (Wordcount ) است، مثال برای ارسال چکیده مقالات، محدودیت وجود دارد، با استفاده از Wordcount تعداد کلمات مشخص میشود و در این اقدام از قابلیت دیجتالی شدن استفاده میشود. ورداسمیت WordSmith و اَنت کانک Antconc از ابزارهای تحلیل متن (پیکره) تخصصی به شمار میروند. نرمافزار آرک جی آی اس (ArcGIS)ابزاری برای تحلیل نقشه است و در تمامی حوزهها کاربرد دارد. از نرمافزار اطلس تی آی Atlas.ti برای تحلیل دادههای دیداری (کیفی) میتوان استفاده کرد. در دادههای ساختار یافته، معمولاً از تحلیلهای آماری استفاده میشود. همانطور که پیشتر اشاره شد، ممکن است گردآوری از طریق مصاحبه یا ضبط ویدیویی صورت گیرد، در چنین شرایطی نیاز به پیاده سازی داده است که برای این کار نیز نرمافزارهای مختلفی در دسترس است، مانند اسپیچ نونس speechnotes و آی او تایپ aiotype. میکروسافت اَکسس Microsoft Access نرمافزاری برای مدیریت پایگاه داده است؛ اِکسل Excel که اغلب پژوهشگران با آن آشنا هستند، برای تحلیلهای آماری، تهیه جدول و نمودار استفاده میشود. پرات praat نرمافزاری که تحلیلهای آکوستیک از صوت و گفتار را ممکن میسازد. تول باکس Toolbox بیشتر در حوزه مدیریت و تحلیل داده بهکار میرود و از ابزارهای کارمیدانی است. ترانسانا transana برای تحلیل داده صوتی و تصویری به کار میرود. همه این ابزارها بهعنوان ابزارهای کاربردی در حوزه علوم انسانی شناخته میشوند؛ تمامی این نرمافزارها و ابزارها برنامههای آموزشی آنها در یوتیوب Youtube موجود است و میتوان شیوه کار با نرمافزارها را آموخت. در ادامه دو ابزار و روش کاربردی در حوزه تحلیل گفتمان بهاختصار معرفی میشوند.
ورداسمیت ابزاری برای تحلیل پیکره، متن و مبتنی بر واژه است که در تحلیلهای زبانی کاربرد فراوان دارد. درونداد آن پِلِین تکست plain text است. در استفاده از این ابزار تحلیل گفتمان پیکره_بنیاد تهیه پیکره مناسب از اهمیت بسیاری برخوردار است. نرمافزار قادر است، پیکره ای را که شما به آن میدهید، از منظرهای گوناگون و با توجه به رخداد واژهها و روابط واژگانی تحلیل کند. بهعنوان نمونه، این قابلیت را دارد که به پژوهشگر اطلاع دهد هر واژه چه تعداد و درصدی رخداد داشته است و با مقایسه پیکره با یک پیکره مبنا کلیدواژههای پیکره مورد بررسی و درصد کلیدواژگی را مشخص میکند. همچنین، بافت رخداد واژه و واژههای همآیند با آن را، با ارائه آمار در اختیارتان قرار میدهد. به نمونهای از تحلیل ارائه شده میتنی بر خروجی نرمافزار ورداسمیت از سخنرانی نامزدهای انتخابات ریاست جمهوری ایران در سال 1400 (رستمبیک، 1401) توجه کنید. البته لازم به تأکید است که در تحلیل نتایج بهدست آمده از نرمافزار، پژوهشگر باید از تواناییهای تحلیلی خود استفاده کند و صرف تحلیل آماری ارائه شده توسط نرمافزار برای انجام تحلیل گفتمان نمیتواند کافی باشد. بهمنظور تحلیل گفتمان سخنرانیهای نامزدهای ریاست جمهوری 1400 ایران، ابتدا مجموع سخنرانیها و مناظرههای هر یک از نامزدها در پیکرههای مجزا گردآوری شد. هر پیکره بهطور مجزت رد نرمافزار تحلیل و سپس با سایر پیکرهها مقایسه شد تا کلیدواژههای سخنان هر یک از نامزدها بهدست داده شود. اولین خروجی که نرمافزار در اختیار قرار میدهد، فهرست بسامدی است و بر اساس آن میتوان دریافت که کدام واژهها یا به عبارتی موضوعها در سخنان هر یک رخداد بیشتر داشتهاند و بیشتر مورد توجه بودهاند. نرمافزار این قابلیت را دارد که هر واژه را در درون متن نشان دهد و پژوهشگر میتواند بهصورت عمیقتر رخداد واژه در جمله را ببیند. با مقایسه برمبنای باهمآیها collocations میتوان تحلیلی دقیقتر مبتنی بر پیکره و نه نظر شخصی از متن ارائه داد. بهعنوان نمونه در سخنان آقای محسن رضایی پس از حذف واژههای دستوری مثل «و»، «که» و ... که بسامد بالایی دارند، پربسامدترین کلمات «استان»، «دولت»، «مردم» و «ایران» بودهاست. مثلاً آقای همّتی، Woordlist از پیکره ایشان تهیه شده شامل کلمات «من»، «مردم» و «باید» پربسامدترین بودهاند. نگاه کنید به تصویر 1-
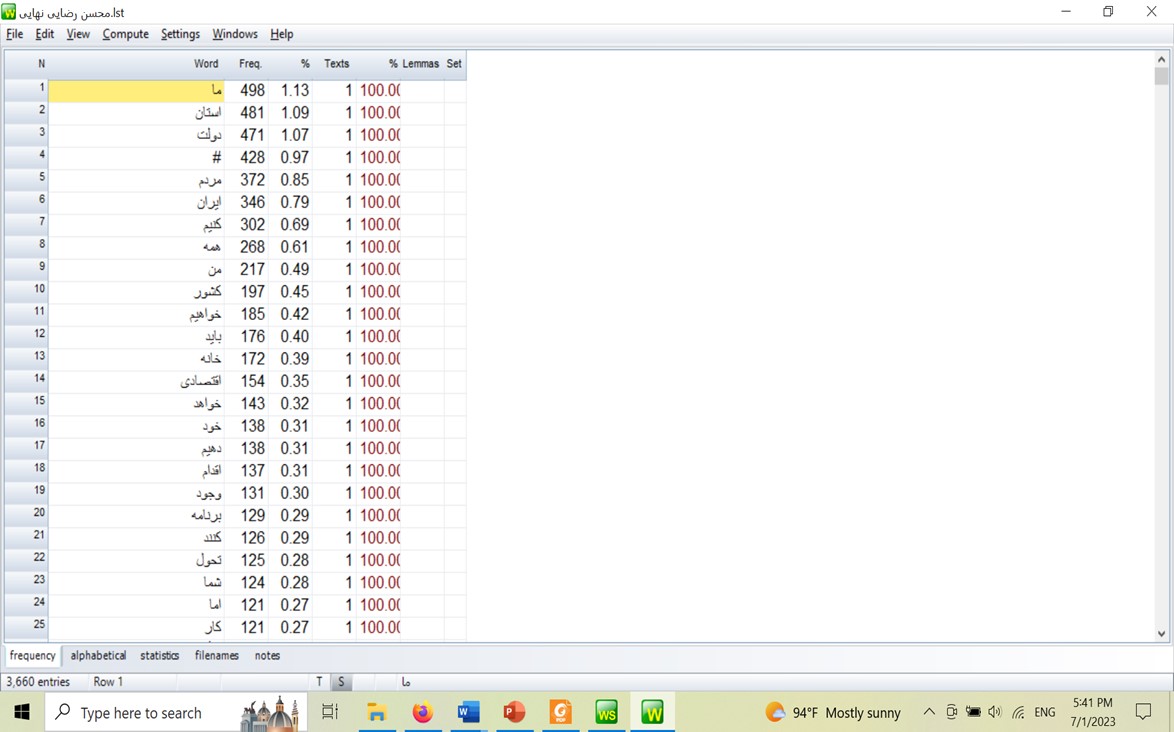
تصویر 1- واژههای پربسامد سخنرانیهای محسن رضایی
مقایسۀ سخنان آقای رئیسی با سایر کاندیدها، کلیدواژههای سخنان او را بهدست میدهد. اولین کلید واژه «عدالت»، «قوّه قضائیه»، «مردم»، «خوزستان»، «آستان قدس» هستند. نگاه کنید به تصویر 2-

تصویر 2- کلیدواژههای سخنان آقای رئیسی
از دیگر امکانات ورداسمیت بهدست دادن ابر کلمات word cloud است که تصویری از کلیدواژهها ارائه میدهد. تصویر 3- ابر کلمات سخنان آقای رئیسی را نشان میدهد.

تصویر 3- ابر کلمات سخنرانیهای انتخاباتی مبتنی بر کلیدواژهها در نرمافزار ورداسمیت
روش دیگری که در تحلیل گفتمان در سالهای اخیر بسیار مورد توجه قرار گرفته است، تحلیل گفتمان چندوجهی است. از اواخر 1980 و اوایل 1990 به این موضوع که معنا صرفاً از طریق زبان منتقل نمیشود، توجه بیشتری شد. بهعبارتی بیان مقصود تنها از طریق کلمات صورت نمیگیرد بلکه ویژگیهای زبرزنجیری کلام چون آهنگ کلام، شدت و بلندی و ... ، حالات چهره، حالت و حرمات بدن و دست و ... در انتقال معنا نقش دارند. موقعیت نشستن، جابهجا شدن روی صندلی، بالابردن شانهها و کلیه حرکات در حال انجام در تحلیلهای چندوجهی تأثیر گذار خواهند بود و به همه این موارد در یک فضا گفتمانی باید توجه شود و خیلی وقتها کلامی ادا نمیشود ولی با حرکات یا زبان بدن یک پیامی منتقل میشود، با توجه به این که معنا فقط از طریق زبان منتقل نمیشود و صوت و تصویر و سایر موارد نیز باید در نظر گرفته شود، تن و لرزش صدا میتواند معنا دار باشد. از این شیوه تحلیل به ویژه برای مطالعۀ رفتار یک جامعه(زبانی) میتواند استفاده شود. گردآوری داده در تحلیل گفتمان چندوجهی با استفاده از ابزارهای ضبط صوت و تصویر یا استفاده از دادههای ویدیویی از پیش ضبط شده امکان پذیر است. در ادامه به نمونهای از تحلیل گفتمان چندوجهی سخنان آقای رئیسی در مناظره اول انتخابات ریاست جمهوری توجه کنید. در این تحلیل از فایل ویدیویی مناظره پخش شده از صدا و سیمای ایران استفاده شده است. به تصویر 4 نگاه کنید. آقای رئیسی هنگامی که دربارۀ تولید و قاچاق صحبت میکنند، در بیان هر دو واژه و به نشانۀ تأمید ابروهایشان را به بالا حرکت میدهند.
ابزار کاربردی دیگری که بهویژه برای ثبت و یا تحلیل داده در مستندسازی زبان و مطالعات حوزه انسانشناسی، جامعهشناسی و قومشناسی کاربرد دارد، ایلن ELAN نام دارد. در گذشته مستندسازی زبان با استفاده از ثبت واژهها و جملات بر روی کاغذ و درنهایت تهیه واژهنامه و کتابهای دستور زبان از گونۀ زبانی مورد بررسی انجام میشد. با پیشرفت تکنولوژی و رایانشی شدن علوم انسانی، ثبت داده صوتی و ویدیویی در کنار پیادهسازی واژهها و جملات اهمیت بسیاری یافته است. تحلیل رفتارهای زبانی یک جامعۀ زبانی بدون ثبت ویدیویی امکانپذیر نخواهد بود. یکی از این ابزارها، ایلن ELAN نام دارد که از ابزارهای پرکاربرد برای حاشیهنویسی تصویر است. تصویر در یک قسمت ایجاد شده است و صوت را میتوان در زمان مشخص متوقف کرد و این امکان وجود دارد که هر کلمه که ادا میشود، نوشته شود و در فضای نرمافزار توضیحی برای آن ارائه و به آن داده اضافه شود (نگاه کنید به تصویر 5)
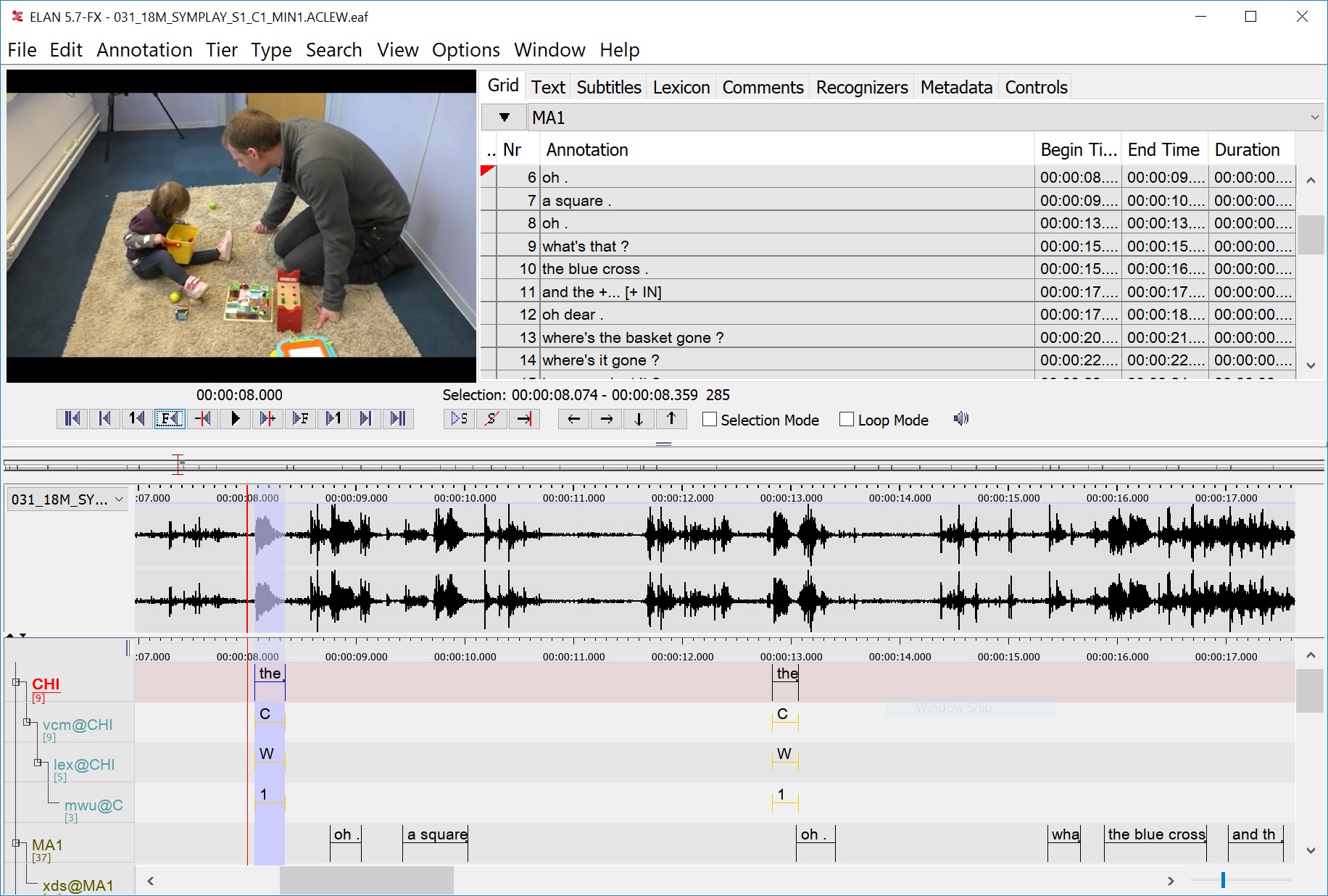
تصویر 5- نمونه ای از فضای ELAN برای حاشیهنویسی فایلهای ویدیویی
به این ترتیب، بهصورت مختصر بیان شد که یک پژوهشگر یا کاربر در حوزه علوم انسانی که از نرمافزارهای مذکور استفاده میکند، چه انتخابهای گسترده پیشرو خواهد داشت بهشرط اینکه آگاهی و امکانات لازم برای او موجود باشد.
نظر شما :